
As a system administrator, you are likely monitoring the disk space on your Linux system all the time, to ensure you can keep on top of any disk capacity issues. Duplicate files on Linux can be a contributor to any free disk space issues you may experience. Duplicate files is one of the first things to address if you are looking to free up space on a Linux system.
This article looks at some of the ways you can find duplicate files on Linux, by exploring some of the duplicate file tools available on Linux with examples of how to use them.
How to Find Duplicate Files with fdupes
Fdupes is a Linux tool which is able to find duplicate files in a specified directory or group of directories. fdupes uses a number of techniques to determine if a file is a duplicate of another. These are, in order of use:
- Size Comparison
- Partial MD5 Signature Comparison
- Full MD5 Signature Comparison
- Byte-to-Byte Comparison
In this section we will look at how to install fdupes and how to use fdupes to find duplicate files on Linux.
How to Install fdupes
To install fdupes on RedHat, CentOS or Fedora, you will first need to enable the epel respository:
$ yum install epel-releaseOnce done, to install fdupes use:
$ yum install fdupesOr, on recent systems you may need to use dnf install fdupes . To install fdupes on Ubuntu systems you can use:
$ sudo apt-get install fdupesWe can confirm it is installed and working by running the fdupes version command:
$ fdupes --version
fdupes 1.6.1OK, so that’s how to install fdupes on Linux. But, how do we use fdupes to find duplicate files?
Find Duplicate Files using fdupes Examples
Lets say we have a bunch of text files in a directory, and we want to find any which are duplicates. My directory listing looks like this:
$ ls -lah
total 48K
drwxrwxr-x 2 cloud_user cloud_user 4.0K Dec 15 11:56 .
drwxr-xr-x 23 cloud_user cloud_user 4.0K Dec 15 11:45 ..
-rw-rw-r-- 1 cloud_user cloud_user 12 Dec 15 11:48 config1.txt
-rw-rw-r-- 1 cloud_user cloud_user 12 Dec 15 11:48 config2.txt
-rw-rw-r-- 1 cloud_user cloud_user 12 Dec 15 11:48 config3.txt
-rw-rw-r-- 1 cloud_user cloud_user 12 Dec 15 11:48 config4.txt
-rw-rw-r-- 1 cloud_user cloud_user 18 Dec 15 11:56 file1.txt
-rw-rw-r-- 1 cloud_user cloud_user 18 Dec 15 11:56 file2.txt
-rw-rw-r-- 1 cloud_user cloud_user 18 Dec 15 11:56 file3.txt
-rw-rw-r-- 1 cloud_user cloud_user 18 Dec 15 11:56 file4.txt
-rw-rw-r-- 1 cloud_user cloud_user 12 Dec 15 11:48 test1.txt
-rw-rw-r-- 1 cloud_user cloud_user 12 Dec 15 11:48 test2.txtAll the files starting with the same word – e.g. File1 – 4 all have the exact same content. Likewise for the config.txt files and the test.txt files. I created the files by echoing the same words into each group of files, this is a quick and easy way to generate a bunch of identical files:
$ for i in {1..5}; do echo "Hello World" > test${i}.txt ; doneSo what happens if we now run fdupes in this directory?
$ fdupes -S .
12 bytes each:
./test1.txt
./test2.txt
12 bytes each:
./config2.txt
./config1.txt
./config3.txt
./config4.txt
18 bytes each:
./file3.txt
./file2.txt
./file1.txt
./file4.txt I’ve used the -S switch to also output the file size. fdupes has grouped all identical files within this directory together which shows that text1.txt for example, is identical to test2.txt. We can use the -m option to get this information, or summary:
$ fdupes -Sm .
7 duplicate files (in 3 sets), occupying 102 bytes.Using fdupes to search for duplicate files recursively or in multiple directories
Searching in a single directory can be useful, but sometimes we may have duplicate files buried in layers of sub-directories. To have fdupes find duplicates recursively the -r option can be used:
$ fdupes -Sr .Alternatively, you can specify the directories you want to target, if you what to check multiple directories. For example:
$ fdupes -S /home/clouduser/documents /home/clouduser/backupDelete duplicate files using fdupes
fdupes has an option to allow you to delete the duplicates you find. I’d suggest using caution before deleting anything unless you are absolutely sure it is safe to do so, and that you have a backup to recover from if you need to! That said, you can delete duplicate files using fdupes by using the -d option. When you run this, you will be prompted for which file you wish to keep out of each set of duplicates that have been identified:
$ fdupes -Sd .
[1] ./test1.txt
[2] ./test2.txt
Set 1 of 3, preserve files [1 - 2, all] (12 bytes each):Alternatively, the -N option can be used, which will preserve the first file out of each set, but won’t prompt:
$ fdupes -SdN .
[+] ./config2.txt
[-] ./config1.txt
[-] ./config3.txt
[-] ./config4.txt
[+] ./file3.txt
[-] ./file2.txt
[-] ./file1.txt
[-] ./file4.txtMy resultant directory listing now looks like this, with all the duplicates removed:
$ ls -lah
total 20K
drwxrwxr-x 2 cloud_user cloud_user 4.0K Dec 15 13:49 .
drwxr-xr-x 23 cloud_user cloud_user 4.0K Dec 15 11:45 ..
-rw-rw-r-- 1 cloud_user cloud_user 12 Dec 15 11:48 config2.txt
-rw-rw-r-- 1 cloud_user cloud_user 18 Dec 15 11:56 file3.txt
-rw-rw-r-- 1 cloud_user cloud_user 12 Dec 15 11:48 test1.txtSo, that’s how to find and remove duplicate files on Linux using fdupes. Next we will take a look at another tool for finding duplicate files, fslint.
Find Duplicate Files using FSlint
FSlint can be used search for and remove duplicate files, empty directories or files with incorrect names. Here we will explore how it can be used to find duplicate files, using the CLI, though there is a GUI mode available also. First of all FSlint will need to be installed:
$ sudo apt-get install fslint <---- Unbuntu
$ sudo yum install fslint <---- RedHat / CentOSNow, when you are running fslint from the CLI, the command will not be available in your PATH, so you will either need to add it, or run the command directly from its install location, which is /usr/share/fslint/fslint on Ubuntu. To check it is installed correctly, use the version option:
$ /usr/share/fslint/fslint/fslint --version
FSlint 2.44List Duplicate Files using FSlint
To list duplicate files in a given directory using fslint, the following syntax can be used:
$ /usr/share/fslint/fslint/fslint /home/cloud_user/myfiles
-----------------------------------file name lint
-------------------------------Invalid utf8 names
-----------------------------------file case lint
----------------------------------DUPlicate files
list1.txt
list2.txt
list3.txt
list4.txt
list5.txt
test1.txtAs you can see, fslint has identified a number of duplicate files. Though fslint doesn’t have an option to remove the duplicate files after they have been identified, it does give you a list to work with.
The last tool for finding duplicate files is called Rdfind.
Find Duplicate Files using Rdfind
Rdfind is a program that finds duplicate files. It compares files based on their content in order to find duplicates. You can install Rdfind using the usual methods depending on your system:
$apt-get install rdfind # Debian/Ubuntu
$dnf install rdfind # FedoraOnce installed, we can run rdfind within the directory we want to examine for duplicates, using:
$ rdfind .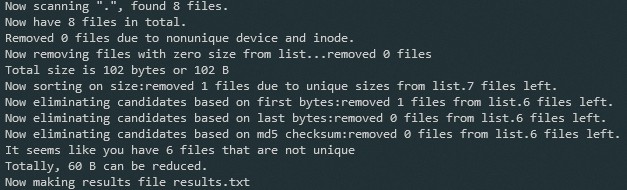
The output shows that rdfind has found 6 files that don’t appear to be unique, and has written the results to a file called results.txt, which looks like this:
$ cat results.txt
# Automatically generated
# duptype id depth size device inode priority name
DUPTYPE_FIRST_OCCURRENCE 3 0 12 66305 1024232 1 ./list1.txt
DUPTYPE_WITHIN_SAME_TREE -3 0 12 66305 1024233 1 ./list2.txt
DUPTYPE_WITHIN_SAME_TREE -3 0 12 66305 1024234 1 ./list3.txt
DUPTYPE_WITHIN_SAME_TREE -3 0 12 66305 1024235 1 ./list4.txt
DUPTYPE_WITHIN_SAME_TREE -3 0 12 66305 1024236 1 ./list5.txt
DUPTYPE_WITHIN_SAME_TREE -3 0 12 66305 1024120 1 ./test1.txt
# end of fileWe could also have rdfind delete the duplicates it identifies, though as with fdupes, use caution when running this command as it will go ahead and delete those files. To delete the duplicates you can use:
$ rdfind -deleteduplicates true .Alternatively, you have the option of replacing the duplicate files with hard links:
$ rdfind -makehardlinks true .
Now scanning ".", found 9 files.
Now have 9 files in total.
Removed 0 files due to nonunique device and inode.
Now removing files with zero size from list...removed 0 files
Total size is 558 bytes or 558 B
Now sorting on size:removed 2 files due to unique sizes from list.7 files left.
Now eliminating candidates based on first bytes:removed 1 files from list.6 files left.
Now eliminating candidates based on last bytes:removed 0 files from list.6 files left.
Now eliminating candidates based on md5 checksum:removed 0 files from list.6 files left.
It seems like you have 6 files that are not unique
Totally, 60 B can be reduced.
Now making results file results.txt
Now making hard links.
Making 5 links.Conclusion
In this article you have learnt a number of ways to find duplicate files on Linux, including using fdupes, fslint and rdfind. We have also covered how to delete duplicate files on Linux using those same tools (use caution, and have a backup!). Alternatively you could look at renaming the files.