The settings on the NIC Teaming tab of a vSwitch or portgroup determine how network traffic traverses the network adapters in an ESXi host and how to respond to changes in network connectivity as a result of a physical adapter failure.
The Failover and Load Balancing policies include three elements that can be configured:
- Load Balancing policy: This determines how outgoing traffic is distributed across the physical network adapters assigned to the vSwitch.
- Failover Detection: There are two options here – Link Status or Beacon Probing
- Network Adapter Order (Active/Standby)
If you are using a standard vSwitch, these options can be found in the vSphere client by browsing to the Configuration | Networking screen and selecting ‘properties’ for the required vSwitch. In the dialog box, click the vSwitch, or a portgroup, then select the NIC Teaming tab.
To change these options on a dvSwitch you can configure either on the uplinks or at the port group level:
Load Balancing Policies
There are a number of options here (with an additional one if you are using a dvSwitch):
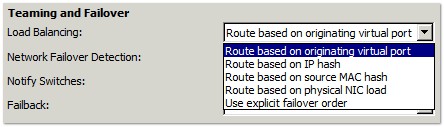
- Route based on the originating port ID: This load balancing setting will select a physical uplink/NIC based on the originating virtual port where the traffic first entered the vSwitch. This is the default load balancing policy on both standard and distributed vSwitches. When using this policy a single VM NIC cannot get more bandwidth than is available on a single physical NIC.
- Route based on IP hash: This load balancing setting will select a physical uplink based on a hash produced using the source and destination IP address. This results in a higher CPU overhead but a better distribution of bandwidth across the physical uplinks connected to the vSwitch. This means a single VM nic can potentially make use of greater bandwidth than that of a single physical NIC. To use ‘Route on IP hash’ the physical uplinks must be configured as an etherchannel on the physical switch. All port groups that use the same uplinks should use the IP Hash policy.
- Route based on source MAC hash: This load balancing policy also uses hashing, however it is based on the source MAC address rather than IP and doesn’t require any additional port configuration on the physical switch.
- Use explicit failover order: This load balancing setting uses the physical NIC that is listed first under Active Adapters.
- Route based on Physical NIC load: This policy is only available for use on distributed vSwitches. This setting determines which network adapter traffic is sent through based on the actual load of the physical NICs. This achieves true load balancing, and no additional physical switch configuration is required for it to work.
Network Failover Detection
There are two options for network failover detection.
- Link Status only: This will detect the link state of the physical adapter. If the link state changes, for example, if the physical switch fails or the network cable is unplugged, failover to a working NIC will be initiated. Link Status works by checking physical (layer 1) connectivity. It is not able to determine or react to configuration issues such as misconfigured VLANs on trunks.
- Beacon Probing: When this setting is enabled, beacon probes are sent out and listened for on all the NICs that are in the team. It uses the probes it receives to determine the link status, and, unlike the Link Status detection method, is able to detect downstream switch failures. Beacon probing works best when there are at least 3 NICs in the team. You can read more about it here. Note: Do not use beacon probing with IP-hash load balancing.
There are some additional settings associated with failover detection.
- Notify Switches. When this is set to ‘Yes’, the host will notify the physical switch the NIC is connected to whenever a failure occurs. Generally this option is set to ‘Yes’, except when a VM using Microsoft NLB in unicast mode is assigned to the port group in question – In which case is should be set to ‘No’.
- Failback. Select Yes or No for the Failback policy. If ‘Yes’ is selected then traffic will fail back to the original NIC once it has recovered following a failure.
Failover Order
The last policy relating to failover and load balancing is the Failover Order policy. This lets you define which adapters are in use, in standby or unused for each vSwitch or portgroup. The three categories available for placing NICs into are:
- Active Adapters: NICs listed here are active and are being used for inbound/outbound traffic.
- Standby Adapters: NICs listed here are on standby and only used when an active adapter fails.
- Unused Adapters: NICs listed here will not be used.
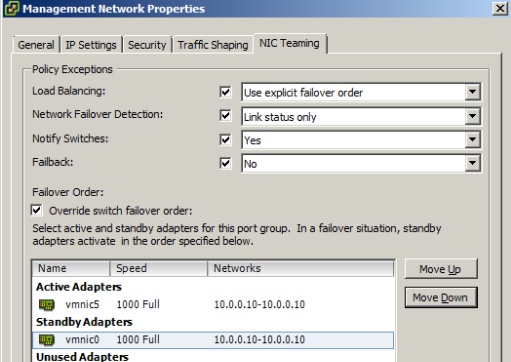
Configure Explicit Failover to Conform with VMware Best Practices
When using Explicit Failover, each portgroup is given its own dedicated network adapter, however also has a standby adapter configured, which is the dedicated adapter for a different portgroup. For example, on the same vSwitch you could have a management portgroup and a vMotion portgroup. vmnic5 would be active for management and standby for vMotion, whilst vmnic0 would be active for vMotion and standby for management. This solution provides each port group with its own dedicated network adapter, effectively isolating it from the impact of any network activity for the others. However, it also allows each port group to be failed over to the remaining network adapters if its own network adapter loses connectivity.
This configuration can be seen in the following images: